该网站对于采集器存在以下限制:
一、验证码限制
在访问频率较高的情况下会出现访问页面需要输入验证码,如下图:
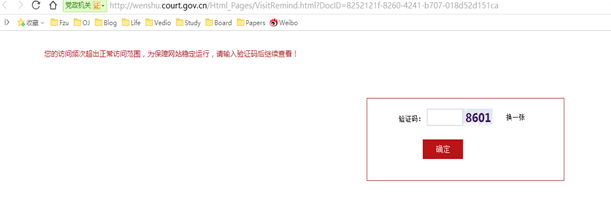
此验证码的生成方式为动态验证码,即每次访问一次验证码生成链接,生成的验证码都不一样,验证码动态生成链接为:
在采集器中如果要进行验证码的识别,需要先下载该验证码的图片,下载需要访问一次该验证码链接,此时的验证码与实际的验证码图片已经不是同一张了,即便识别成功,也会报验证码填入错误。
二、封IP限制
我们人工模拟采集器采集页面,同一个IP,当访问频率达到一定程度时,该网站会直接拒绝访问。如下图:
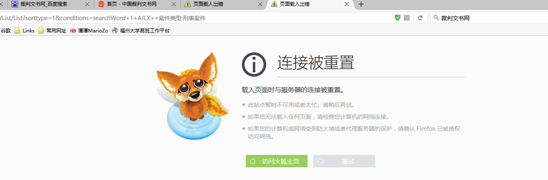
总结:若在采集中出现以上两种情况,将无法继续爬取该网站的内容。